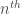Dark Origins
This is a short post about a tough puzzle I came across a few months back, originally at Two Guys Arguing. Since it’s the Matrix Puzzle From Hell, and it’s nearly Halloween, I thought it was ingeniously topical. I’m sure you agree.
If anyone knows the true origin of the puzzle, I’d love to hear it.
The Puzzle
A matrix has the property that every entry is the smallest nonnegative integer not appearing either above it in the same column or to its left in the same row.
Give an algorithm to compute the entries of this matrix.
An Example
Here’s an example matrix:
0 1 2 3 4 5 6 7 1 0 3 2 5 4 7 6 2 3 0 1 6 7 4 5 3 2 1 0 7 6 5 4 4 5 6 7 0 1 2 3 5 4 6 7 1 0 3 2 6 7 4 5 2 3 0 1 7 6 5 4 3 2 1 0
It looks like this matrix is full of patterns, so what’s a good algorithm for computing its entries?
As with any puzzle, it’s probably worth trying it before reading the spoilers below. I’ll reveal the answer slowly though.
A (Very) Naive Algorithm
Without really thinking about the puzzle, we can at least give a correct algorithm. To compute a particular entry, compute all the entries above it, and to its left, and choose the smallest nonnegative integer not included in the union of those two.
If we’re considering an 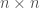
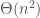

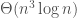
This certainly feels very naive. We’re not using any of the problem’s structure. At least we have a time complexity though.
Patterns
Let’s look at a small example matrix
0 1 2 3 1 0 3 2 2 3 0 1 3 2 1 0
There’s lots of symmetry here, and quite a few patterns to consider. Let’s just look at the top-left 2×2 entries though:
0 1 1 0
To generate the 2×2 sub-matrix of entries in the top-right of our original 4×4 matrix, we just add 2 to these entries. To generate the 2×2 sub-matrix of entries in the bottom-left, we just add 2 to these entries. To generate the 2×2 sub-matrix in the bottom-right, we just copy these entries.
We now have our 4×4 matrix, if we extend it in the same way, adding 4 this time, we’ll get our original 8×8 example matrix.
We can even start with a 1×1 matrix: 0, and extend it into the initial 2×2 matrix, by adding one (and copying).
So this looks like a very useful pattern. We’ve not thought about why, or if, it’s right just yet. It looks right though. So let’s try and bash out a better algorithm.
A Better Algorithm
It looks like we can generate the entire matrix by the “doubling” pattern just described: Start with the 1×1 matrix (which is just 0). Double it to give the 2×2 matrix, double that to give a 4×4 matrix, etc.
To pick out just a single entry, generating the whole matrix isn’t going to be the right way to go though. We’d still only be down to
Instead, we can work backwards. To work backwards from a given row and column 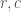

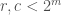
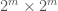
More precisely, we’re saying of our matrix 
- Choose the largest integer
such that
- Choose the largest integer
such that
- If
(i.e. bottom-right quadrant), then the answer is
- If
(i.e. bottom-left quadrant), then the answer is
- If
(i.e. top-right quadrant), then the answer is
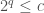
![M[r - 2^p, c - 2^p]](https://s0.wp.com/latex.php?latex=M%5Br+-+2%5Ep%2C+c+-+2%5Ep%5D&bg=ffffff&fg=444444&s=0&c=20201002)
![2^p + M[r - 2^p, c]](https://s0.wp.com/latex.php?latex=2%5Ep+%2B+M%5Br+-+2%5Ep%2C+c%5D&bg=ffffff&fg=444444&s=0&c=20201002)
![2^q + M[r, c - 2^q]](https://s0.wp.com/latex.php?latex=2%5Eq+%2B+M%5Br%2C+c+-+2%5Eq%5D&bg=ffffff&fg=444444&s=0&c=20201002)
Repeating this until we get to 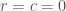
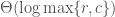
But can we do even better still? It turns out we can. A lot better.
Harder, but Easier
When I first heard this puzzle, there was a condition attached to the time complexity of the solution. If it had been that there is a solution working in 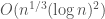
Instead, it said the solution had to work in 
Knowing it can be done in constant time and space means there must be a formula for the entries. Let’s start simple, and go through our tools. Does ![M[r, c] = r + c](https://s0.wp.com/latex.php?latex=M%5Br%2C+c%5D+%3D+r+%2B+c&bg=ffffff&fg=444444&s=0&c=20201002)
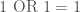
![M[1, 1] = 0](https://s0.wp.com/latex.php?latex=M%5B1%2C+1%5D+%3D+0&bg=ffffff&fg=444444&s=0&c=20201002)
What about XOR? It turns out that’s it. We can just XOR our row and column numbers to get the entry. Try it!
But Why?
It’s a bit of a shocker to know the answer is just plain-old XOR. Who knew it computed the minimum excluded number in a matrix?
Well, if we look at our logarithmic time algorithm, it’s pretty easy to see that it’s nothing more than an XOR of the row and column. When it said “Choose the largest integer 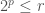
This at least explains how we get to XOR from our quadrant-based algorithm. We still haven’t really explained why our initial “doubling” construction was correct though. Before we do that, let’s have a look at a pretty picture.
Pretty Picture
As a neat little aside, it turns out that if you draw a picture of our matrix (zero being black), here’s what you get:

Pretty much any demoscener (or graphics hacker) will recognize this as the XOR texture, the easiest of all textures to generate. Just try googling it!
Speaking of the demoscene, here’s video of 4k Amiga intro making extensive use of the XOR pattern (not usually a badge of honor in the demoscene world, incidentally): Humus 4.
I think it’s neat to know that texture is all about minimum excluded numbers, after all these years.
But Really, Why?
We never really explained why our doubling construction is actually correct. It’s pretty obvious, but let’s see about that now.
Suppose we have a 

- The upper-left corner is
- The bottom-left corner is the entries of
- The bottom-right corner is
- The upper-right corner is the entries of
Now let’s think about the simplest version of our matrix. If 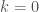
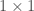

If we apply our doubling construction, we have a 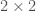
The question is now, in a doubled matrix, is each entry the minimum excluded number? Consider any 

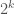
We can make similar arguments for the other two quadrants. That’s another way to see the XOR connection. The upper-left and bottom-left quadrants are restricted in the numbers they can choose as entries because they have only either a different row or a different column (i.e. exclusive or) to the entries in the top-left quadrant. Whereas, the entries in the bottom-right quadrant are unrestricted by those in the top-left quadrant having both a different row and column.
Nim, Nimbers and Beyond
To finish up, it’s worth noting that there’s a kid’s game played with piles of sticks called Nim, which the solution to this puzzle represents a winning strategy for.
In fact, there are even things called Nimbers, and XOR corresponds to Nimber addition. There’s also a Nimber multiplication operator. I wonder what it looks like as a texture, compared to what the XOR texture looks like?
 elements, bubble sort works by performing roughly
elements, bubble sort works by performing roughly  . So it looks like this:
. So it looks like this: time, and we make
time, and we make 
 , and we divide it into
, and we divide it into  stages, we still take time
stages, we still take time  units of time. This is great. There’s a little extra latency for each instruction, but we’ve improved throughput by a factor of
units of time. This is great. There’s a little extra latency for each instruction, but we’ve improved throughput by a factor of 
 be the probability that the
be the probability that the  comparison branch of the inner-loop (i.e. “bubble_sweep”) is taken on the
comparison branch of the inner-loop (i.e. “bubble_sweep”) is taken on the  sweep of bubble sort.
sweep of bubble sort.![\texttt{a[l]}](https://s0.wp.com/latex.php?latex=%5Ctexttt%7Ba%5Bl%5D%7D&bg=ffffff&fg=444444&s=0&c=20201002) is not larger than all of
is not larger than all of ![\texttt{a[0..l - 1]}](https://s0.wp.com/latex.php?latex=%5Ctexttt%7Ba%5B0..l+-+1%5D%7D&bg=ffffff&fg=444444&s=0&c=20201002) . For this to be the case, the
. For this to be the case, the 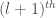 branch in the previous sweep must have been taken, since otherwise the previous sweep left the maximum of
branch in the previous sweep must have been taken, since otherwise the previous sweep left the maximum of 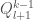 .
. 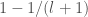 , and so we have:
, and so we have: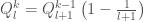
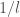 .
.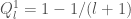 for
for 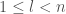 and
and  , we see that when
, we see that when 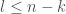 then
then  , and
, and 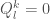 otherwise.
otherwise.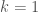 , and the branches are highly likely to be taken, on the other hand, on the last sweep
, and the branches are highly likely to be taken, on the other hand, on the last sweep  and the branches are unlikely to be taken.
and the branches are unlikely to be taken. 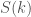 be the average total mispredictions in sweep number
be the average total mispredictions in sweep number  , then we know
, then we know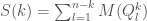 . Where
. Where 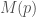 is the probability that a branch that is taken with probability
is the probability that a branch that is taken with probability  . This will of course, lower bound the branch mispredictions, because in reality branch predictors work hard to guess what
. This will of course, lower bound the branch mispredictions, because in reality branch predictors work hard to guess what 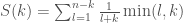 . After a lot of messy algebra we’ll find that
. After a lot of messy algebra we’ll find that 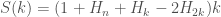 when
when 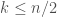 and
and  otherwise (here
otherwise (here  is the
is the